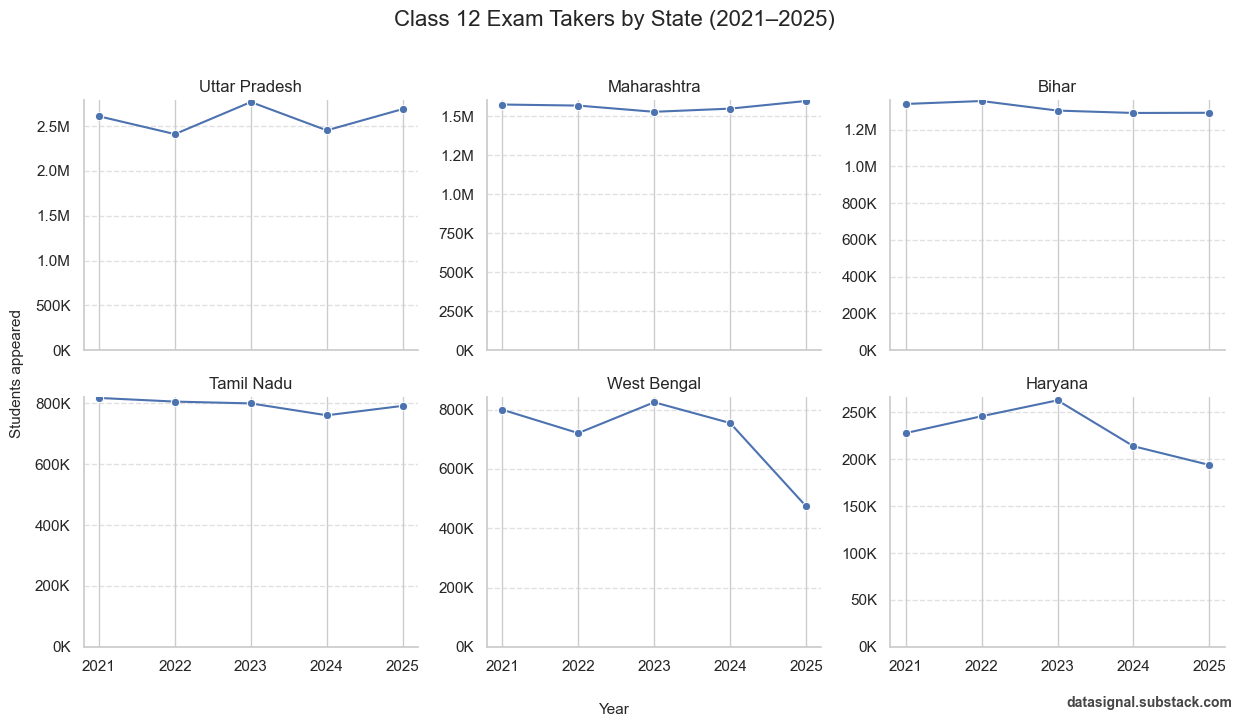
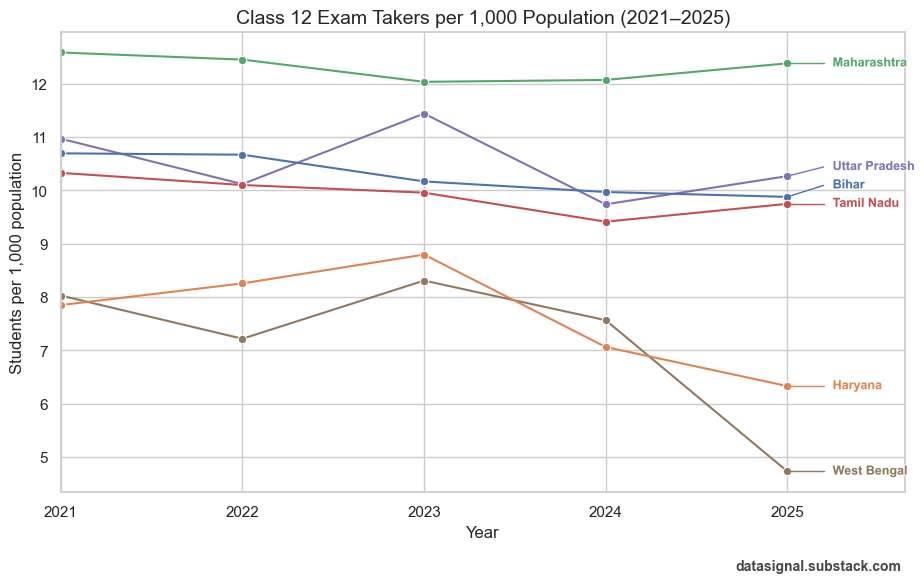
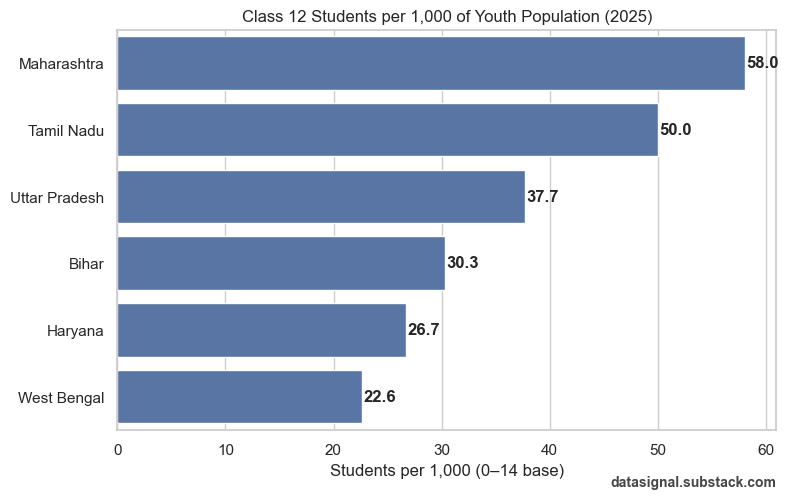
As an Analytics professional, it is our job not to accept whatever is propagated by the belief system blindly. Rather, do our investigation, and then accept, reject, or refine it.
So, I thought, what if we try to see what is actually happening here? In this blogpost, I will discuss my approaches for the same.
But before asking any questions - let’s have a look at the data. What is the gap between the Conte of domestic league and Europe?
For our analysis, we have also taken Pep and Klopp (Liverpool & Dortmund) - so that we can understand how he compares with the other two. This will help us in putting things into more context.
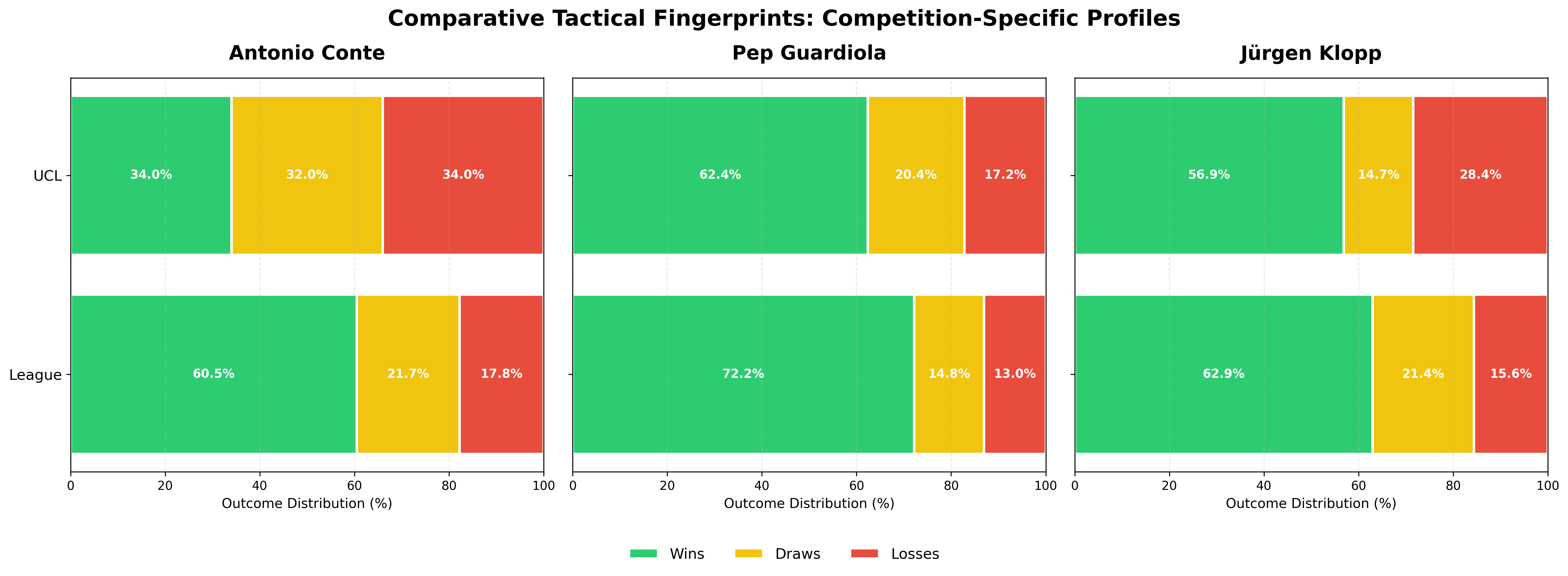
As we can see, there is a significant difference in the win % for Conte - compared to Klopp & Pep.
So the question arises:
Is this a fluke or statistically significant?
A simple Z-test can tell us if the gap in Europe vs Domestic League is just a fluke or if there is some statistical significance.
Turns out - it is highly significant!
The difference is even significant for Pep. Now if you think about it - that is expected. UCL is a tougher competition. So, we would expect to see some reduction in the winning percentage.
For Klopp, though, it is not significant.
┌───────────┬───────────────┬──────────────────┬─────────────┬──────────┬──────────────────────────────┐
│ Manager │ UCL Win Rate │ League Win Rate │ Z-statistic │ P-value │ Interpretation │
├───────────┼───────────────┼──────────────────┼─────────────┼──────────┼──────────────────────────────┤
│ Conte │ 34.0% │ 60.5% │ 3.661 │ 0.000251 │ Highly significant difference│
├───────────┼───────────────┼──────────────────┼─────────────┼──────────┼──────────────────────────────┤
│ Guardiola │ 62.4% │ 72.2% │ 2.540 │ 0.011086 │ Significant difference │
├───────────┼───────────────┼──────────────────┼─────────────┼──────────┼──────────────────────────────┤
│ Klopp │ 56.9% │ 62.9% │ 1.161 │ 0.245760 │ No significant difference │
└───────────┴───────────────┴──────────────────┴─────────────┴──────────┴──────────────────────────────┘
How different are the tactical profiles?
In the first section, we looked at winning % only. Now, let’s examine the complete tactical profile - how the full distribution of wins, draws, and losses shifts between competitions.
The Chi-square test helps us understand if the entire result pattern changes, not just the win rate. And interestingly, even Klopp shows a significant difference here despite his Z-test being non-significant. This suggests his teams play differently in Europe (fewer draws, more decisive results), even though his overall win rate stays similar.
┌───────────┬───────────┬──────────┬────────────┬──────────────────────────────┐
│ Manager │ χ² │ P-value │ Cramér's V │ Interpretation │
├───────────┼───────────┼──────────┼────────────┼──────────────────────────────┤
│ Conte │ 14.136 │ 0.000852 │ 0.145 │ Highly significant difference│
├───────────┼───────────┼──────────┼────────────┼──────────────────────────────┤
│ Guardiola │ 6.441 │ 0.039928 │ 0.092 │ Significant difference │
├───────────┼───────────┼──────────┼────────────┼──────────────────────────────┤
│ Klopp │ 10.336 │ 0.005696 │ 0.127 │ Significant difference │
└───────────┴───────────┴──────────┴────────────┴──────────────────────────────┘
So far, all three managers show some form of difference between their league and UCL performances. But here’s the key question: Is the difference abnormal, or is it just the “Elite Tax” of playing in Europe?
The Elite Tax: Accounting for Expected Difficulty
Now, let’s switch from a frequentist lens to a Bayesian one.
Here’s the fundamental insight: UCL is harder than domestic leagues. You can’t really treat playing Everton and Real Madrid at the same level. So we should expect some performance drop when managers face Europe’s elite. The question isn’t “is there a difference?” but rather “is the difference larger than expected?”
The Methodology: The 10% ROPE
I introduced a Region of Practical Equivalence (ROPE), which I call the “Elite Tax.” I am granting every manager a “pardon” for a 10% drop in win rate. If their win rate drops by 10% or less, we consider that a normal byproduct of elite competition.
I then ran 100,000 simulations for each manager to calculate the probability that their performance drop is abnormal (greater than 10%).
If a manager’s drop is within the 10% zone → Normal (performing as expected given increased difficulty)
If a manager’s drop exceeds 10% → Abnormal (genuine UCL problem)
The Results
┌───────────┬───────────┬────────────────────┬──────────────────────────────────┐
│ Manager │ Mean Drop │ P(Exceeds 10% Tax) │ Interpretation │
├───────────┼───────────┼────────────────────┼──────────────────────────────────┤
│ Conte │ 25.9% │ 98.76% │ Abnormal UCL underperformance │
├───────────┼───────────┼────────────────────┼──────────────────────────────────┤
│ Guardiola │ 9.9% │ 48.36% │ Normal (within expected range) │
├───────────┼───────────┼────────────────────┼──────────────────────────────────┤
│ Klopp │ 6.1% │ 23.18% │ Normal (well within range) │
└───────────┴───────────┴────────────────────┴──────────────────────────────────┘
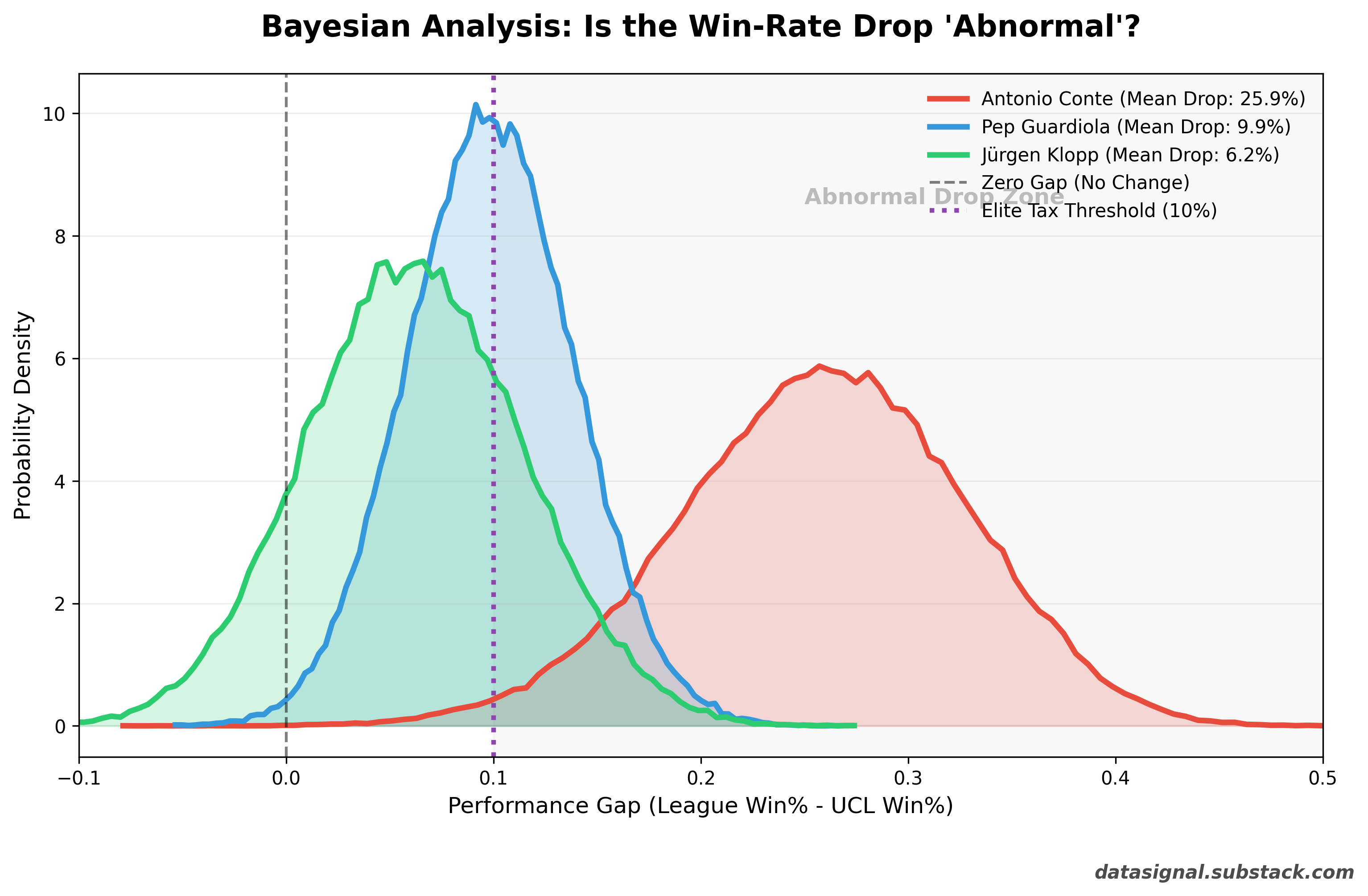
What This Means
Pep Guardiola: The Benchmark. Pep’s distribution is centered almost perfectly on our 10% “Elite Tax” line. With a 48% chance of exceeding that threshold, his performance is essentially a coin flip. Mathematically, he is performing exactly how an elite manager should in a tougher competition.
Jürgen Klopp: The Outlier (The Good Kind). Klopp’s entire distribution is tucked safely to the left of the 10% line. There is only a 23% chance that his drop-off is abnormal. But here’s the interesting part: his Z-test showed no significant win rate difference, yet his Chi-square test was significant. Why? Because his tactical approach shifts in Europe - fewer draws, more decisive results - even though his overall win rate stays similar. He doesn’t win less in the Champions League; he just plays differently. More high-stake matches, all-or-nothing football. If anything, Klopp is competition-proof; his tactical identity survives the jump from domestic leagues to Europe better than Pep or Conte.
Antonio Conte: The “Statistical Glitch.” Conte lives in a different zip code. With 98.7% certainty, the model confirms that his European drop-off is abnormal. Even after accounting for his smaller UCL sample size (which makes his curve wider), there is almost zero overlap between his reality and that of Pep or Klopp.
How to read the plot: Don’t just look at the peaks of the curves. Look at where they don’t overlap. Pep and Klopp’s performance distributions live in the same neighborhood. Conte’s distribution doesn’t even have a view of their street.
The Verdict
Statistics confirm what the eye test suggested: Only Conte has a genuine UCL problem.
While all three managers show some performance difference between competitions (as they should - the UCL is harder), only Conte’s gap is abnormal after accounting for the increased difficulty. Pep and Klopp are performing within the expected range for elite managers facing elite opposition.
The “Tale of Two Contes” is a real, quantifiable pattern that has persisted across 50 Champions League matches and 618 league games. Whether it’s tactical inflexibility in knockout rounds, squad depth issues, or something else entirely - the numbers make one thing clear: domestic dominance doesn’t automatically translate to European success.
Link to the notebook: https://github.com/shibaprasadb/datasignal/blob/main/conte_record/conte_record.ipynb
]]>